


Master Web Scraping with Python: A Beginner's Guide using Beautiful Soup
"Unlock the Power of Data Extraction with Python's Beautiful Soup - A Comprehensive Guide for Beginners"


Attention Data Enthusiast! 📊👩💻
If you're interested in extracting web data using Python, look no further than the powerful and user-friendly Beautiful Soup package! Popular Python web scraping package called Beautiful Soup is utilised. Using an easy-to-understand syntax, it enables users to explore HTML and XML documents and extract data from them. We'll go over the steps needed to utilise Beautiful Soup to extract data from a website in this blog article.
Steps to Extract Data from HTML using Beautiful Soup
Step 1: Install Beautiful Soup
Before using Beautiful Soup, you need to install it. You can do this by running the following command in your terminal:
Copy codepip install beautifulsoup4
Step 2: Import the Required Libraries
Once Beautiful Soup is installed, you need to import it, along with any other libraries you'll be using, such as requests for fetching the HTML content.
pythonCopy codefrom bs4 import BeautifulSoup
import requests
Step 3: Fetch the HTML Content
To extract data from a website, you first need to fetch the HTML content of the web page you want to scrape. You can do this using the requests library, which allows you to make HTTP requests to a website.
pythonCopy codeurl = 'https://example.com'
response = requests.get(url)
html_content = response.content
Step 4: Parse the HTML Content Using Beautiful Soup
Once you have the HTML content, you need to parse it using Beautiful Soup. You can do this by creating a BeautifulSoup object, passing the HTML content and the parser you want to use as arguments.
pythonCopy codesoup = BeautifulSoup(html_content, 'html.parser')
Step 5: Extract the Data
Finally, you can extract the data you want from the parsed HTML content. You can do this by using the various methods provided by Beautiful Soup, such as find_all() to find all instances of a specific HTML tag, or select() to find elements based on CSS selectors.
pythonCopy code# Extract all links from the HTML content
links = soup.find_all('a')
# Extract the text content of all paragraphs
paragraphs = soup.select('p')
text_content = [p.get_text() for p in paragraphs]
In conclusion, the Python web scraping package Beautiful Soup is a potent and user-friendly tool. You can use Beautiful Soup to quickly extract data from any website by following the instructions above.
Screenshots
You can also look at the screenshots of the Code.

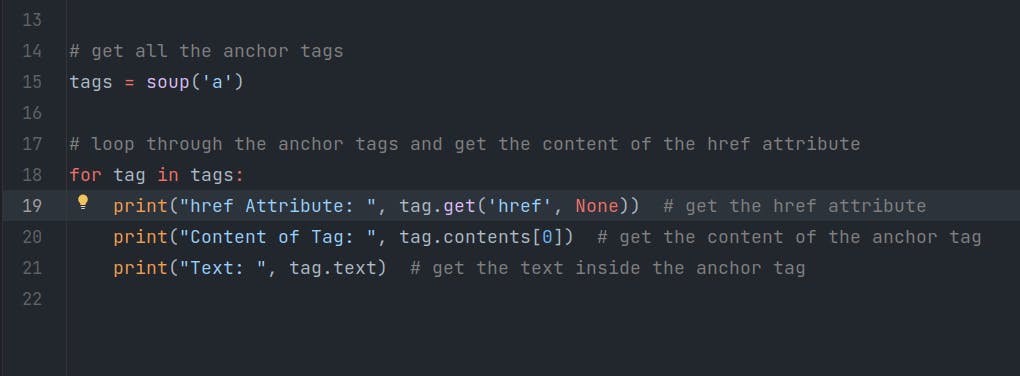
Note
However, it's crucial to keep in mind that online scraping may be a legally murky area. As a result, before scraping any website, make sure to verify the terms of service or get legal counsel.
If you found this example useful, be sure to save and share it with your data enthusiast friends!